
背景介绍
执行流程
典型的CUDA程序的执行流程如下:(host指代CPU及其内存,device指代GPU及其内存)
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
函数类型限定词
__global__:在在device上执行,从host中调用。返回类型必须是void,不支持可变参数参数,不能成为类成员函数。用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
线程层次结构
kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。
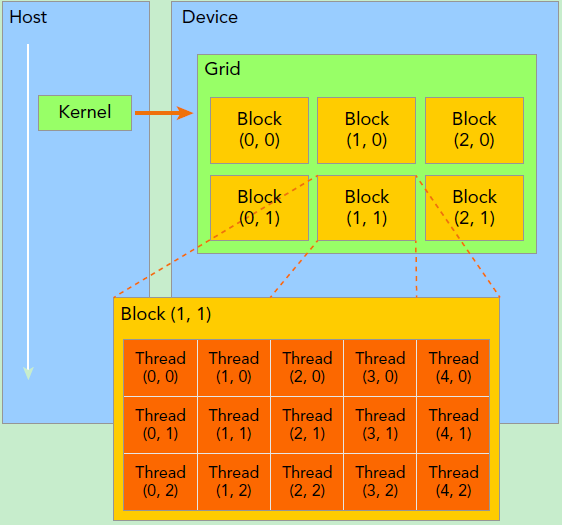
grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对于图中结构(主要水平方向为x轴),定义的grid和block如下所示,kernel在调用时也必须通过执行配置<<<grid, block>>>来指定kernel所使用的线程数及结构。
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<< grid, block >>>(prams...);
因此,一个线程需要两个坐标变量(blockIdx,threadIdx)来进行定位,它们都是dim3类型的变量。其中blockIdx表示线程所属的block在grid中的索引,threadIdx表示线程所在block中的索引。
物理层结构
- GPU硬件的一个核心组件是SM。
- SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。
实例
矩阵加法
Q:对两个N×N维的矩阵进行对应位置相加。
A:对于此种逐点运算,通用处理思路就是每个thread处理一个位置的运算,与此类似的还有矩阵相乘等。代码如下:
// Kernel定义
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
//每个thread都会执行这个核函数,i和j唯一确定了当前的thread
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel 线程配置
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// kernel调用 和__global__照应 在host中调用 在device中执行
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
矩阵乘法
首先定义矩阵的结构体:
struct Matrix
{
int width;
int height;
float *elements;
};
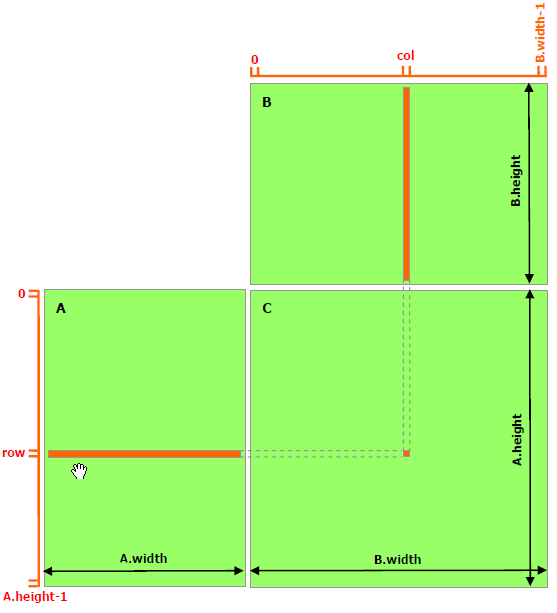
这里假设A为3×4的矩阵,B为4×2的矩阵。
根据笔者理解,在CUDA核的计算过程设计中,比较重要的一点就是选择最小的计算式,即一个thread中需要执行的运算。确定最小计算式后就可以根据问题规模确定我们所需要的threadPerBlock和BlockPerGrid的数量。由上图分析可以假设在矩阵运算中最小计算式为A矩阵中第i行元素和B矩阵中第j列元素求点积得到
C[i][j]元素值的过程。那么在示例中这样的运算我们需要执行3×2次,可以用dim2型来进行索引,一个thread也就可以通过两个坐标row, col来确定,正好对应于3×2。
获取元素值的函数为:
__device__ float getElement(Matrix *A, int row, int col)
{
return A->elements[row * A->width + col];
}
为指定位置元素赋值的函数为:
__device__ void setElement(Matrix *A, int row, int col, float value)
{
A->elements[row * A->width + col] = value;
}
矩阵相乘的核函数为:
__global__ void matMulKernel(Matrix *A, Matrix *B, Matrix *C)
{
float Cvalue = 0.0;
int row = threadIdx.y + blockIdx.y * blockDim.y;
int col = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = 0; i < A->width; ++i)
{
Cvalue += getElement(A, row, i) * getElement(B, i, col);
}
setElement(C, row, col, Cvalue);
}
可能遇到的问题
线程不够用
grid-stride-loop 技巧:假设任务需求为1000,但是只有250个thread,那么每个thread就需要重用4次,即每个thread需要执行4次操作。stride即为总的thread数量,比如thread[0]需要计算0, 250, 500, 750,通过这样的方式让线程得到重复利用。
NVIDA原生算子
cuDNN:经常用于DNN的应用,如
- Convolution 卷积
- pooling 池化
- Softmax
- 激活函数(Sigmoid, ReLU …etc)
cuBLAS:处理矩阵运算的函数库,能够支持多种精度(单精度, 双精度,…etc)的运算