
Starting Simple
#include <iostream>
#include <math.h>
// function to add the elements of two arrays
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20; // 1M elements
float *x = new float[N];
float *y = new float[N];
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the CPU
add(N, x, y);
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
delete [] x;
delete [] y;
return 0;
}
编译运行:
$ g++ add.cpp -o add
$ ./add
Max error: 0
如果想要把程序放在GPU上执行,则需要把函数变成GPU可以运行的,也称之为kernal in CUDA。方法是在函数前面加一个sprcifier__global__,说明其执行是在GPU中,调用是在CPU中,更改后的add函数如下:
// CUDA Kernel function to add the elements of two arrays on the GPU
__global__
void add(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
Memory Allocation in CUDA
Unified Memory in CUDA makes this easy by providing a single memory space accessible by all GPUs and CPUs in your system. To allocate data in unified memory, call cudaMallocManaged(),To free the data, just pass the pointer to cudaFree().
代码迁移也仅仅是把C++中的new内存分配操作替换成cudaMallocManaged(),把delete操作替换成cudaFree,相应代码如下:
// Allocate Unified Memory -- accessible from CPU or GPU
float *x, *y;
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
...
// Free memory
cudaFree(x);
cudaFree(y);
C++中的函数调用也变为了cuda kernel的启动,下面的代码启动了一个GPU线程来运行add函数。
add<<<1, 1>>>(N, x, y);
为了在CUDA kernel执行完毕后才使CPU访问结果,可以通过cudaDeviceSynchronize()来进行同步。
CUDA C++的编译需要使用nvcc,编译运行结果为:
> nvcc add.cu -o add_cuda
> ./add_cuda
Max error: 0.000000
Profile it?
通过nvprof运行可以看到运行所花费的时间。
$ nvprof ./add_cuda
Picking up the Threads
GPU运行快的大部分原因是其并行化,其实现是基于更多的thread来进行加速。如何使其并行化呢?关键在于<<<1, 1>>>,这被称为执行配置,它告诉CUDA要使用多少个并行线程。
让我们从改变第二个参数开始,第二个参数代表在一个thread block中的thread的数量。
add<<<1, 256>>>(N, x, y);
CUDA C++ provides keywords that let kernels get the indices of the running threads. Specifically, threadIdx.x contains the index of the current thread within its block, and blockDim.x contains the number of threads in the block.
__global__
void add(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
Out of the Blocks
The first parameter of the execution configuration specifies the number of thread blocks.Together, the blocks of parallel threads make up what is known as the grid.
Example:当我有N个元素要去处理,每个block有256个线程,其计算方式为:
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, x, y);
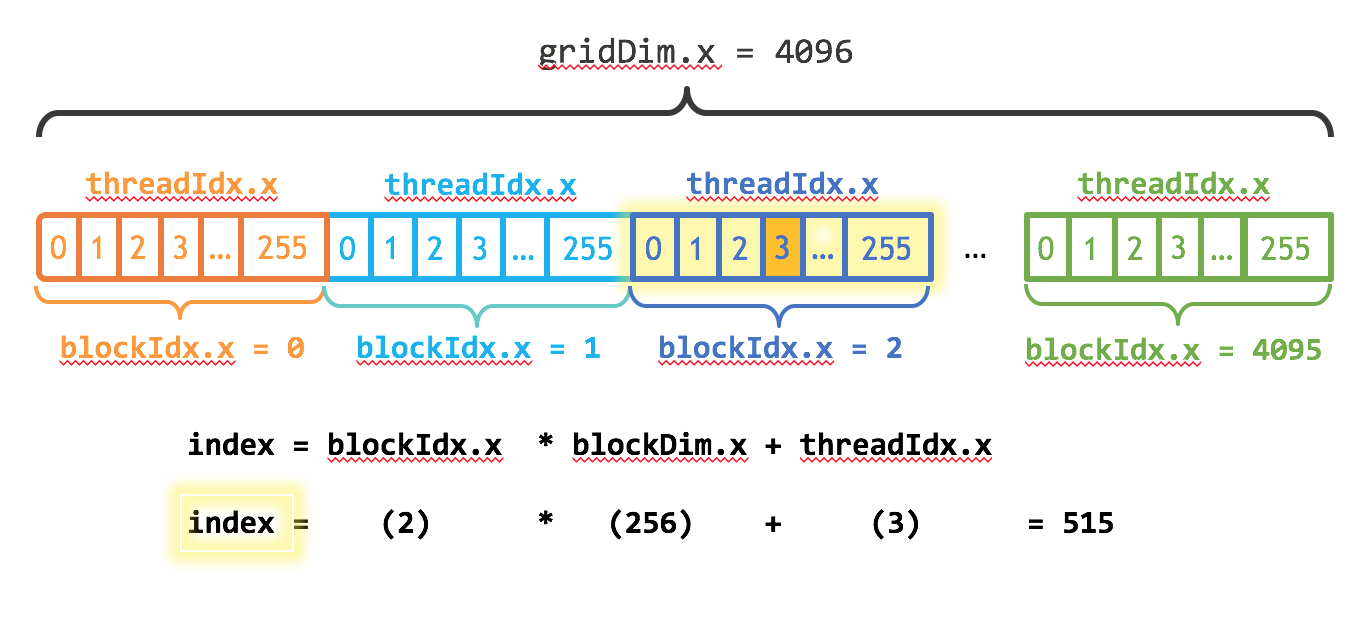
- gridDim.x表示每个grid中block的个数
- blockIdx.x表示当前线程block在grid中的idex
如此对代码进行改进:
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}